算力市场
算力实例
算力集群
AI 工具
模型服务
Agent 服务
AI 搜索
帮助文档
关于我们
EN
算力集群
采用高性能裸金属GPU服务器作为节点,使用RDMA(Remote Direct Memory Access)技术实现互联,提供高带宽和超低延迟的网络服务。该集群能够将复杂的计算任务高效分配至多个节点并行处理,以满足高性能计算、大规模模型训练、智能搜索等应用场景的并行计算需求,带来更加卓越的计算能力和性能表现。
立即体验
产品功能
立即体验 >>
高性能裸金属算力
RDMA高性能网络互联
分布式智算资源池
基于高性能裸金属服务器架构,无虚拟化或容器化管理损耗。
提供快速部署,物理服务器可在分钟级时间内获取。
满足企业对数据安全和可靠性的需求。
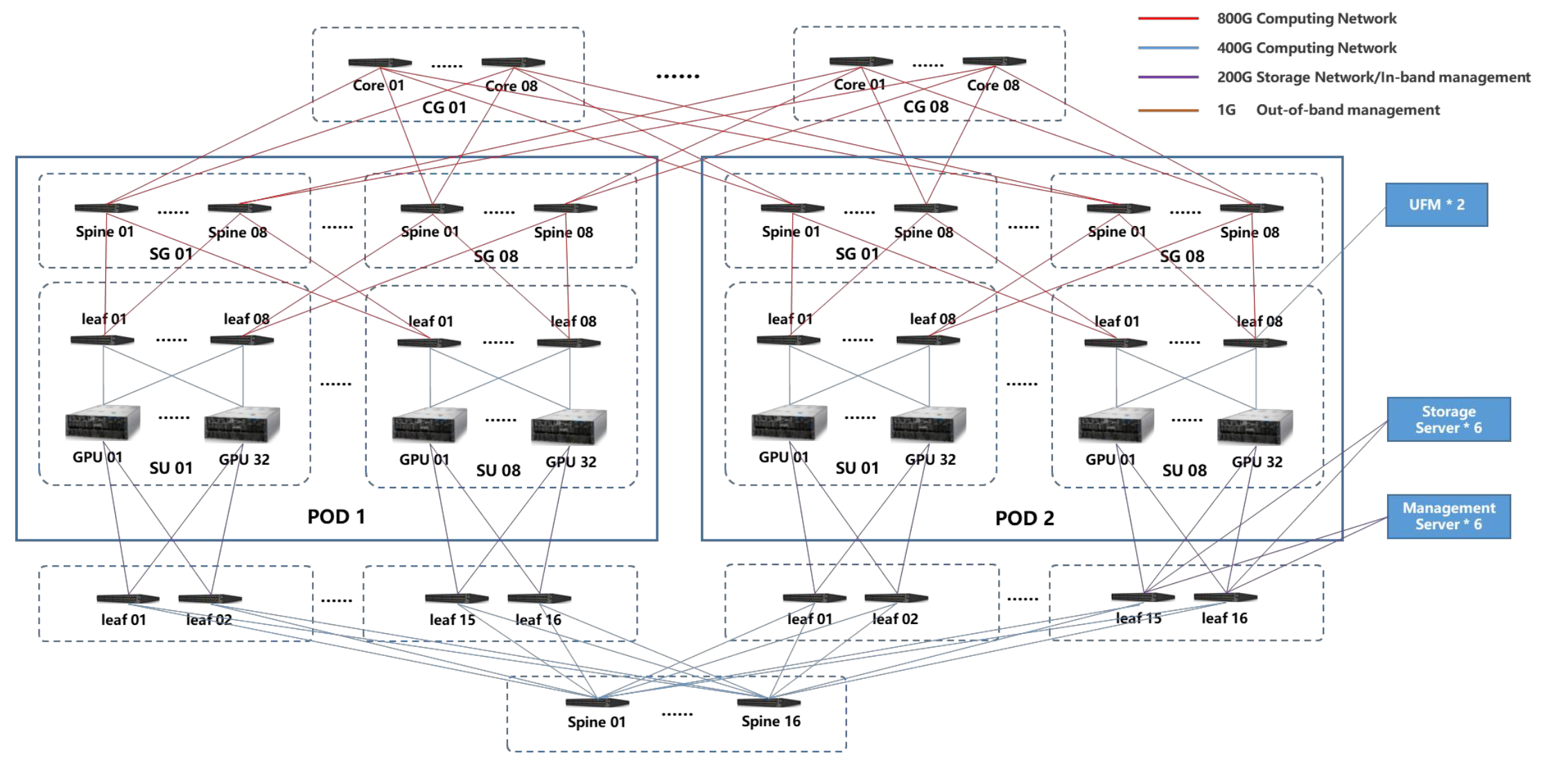
GPU 节点通过 400Gbps 的 InfiniBand 或自研 RoCE 协议的 RDMA 高速网络连接。
集群内节点间最高可实现 3.2Tbps 的互联速度。
支持海量数据的高效并行计算加速。
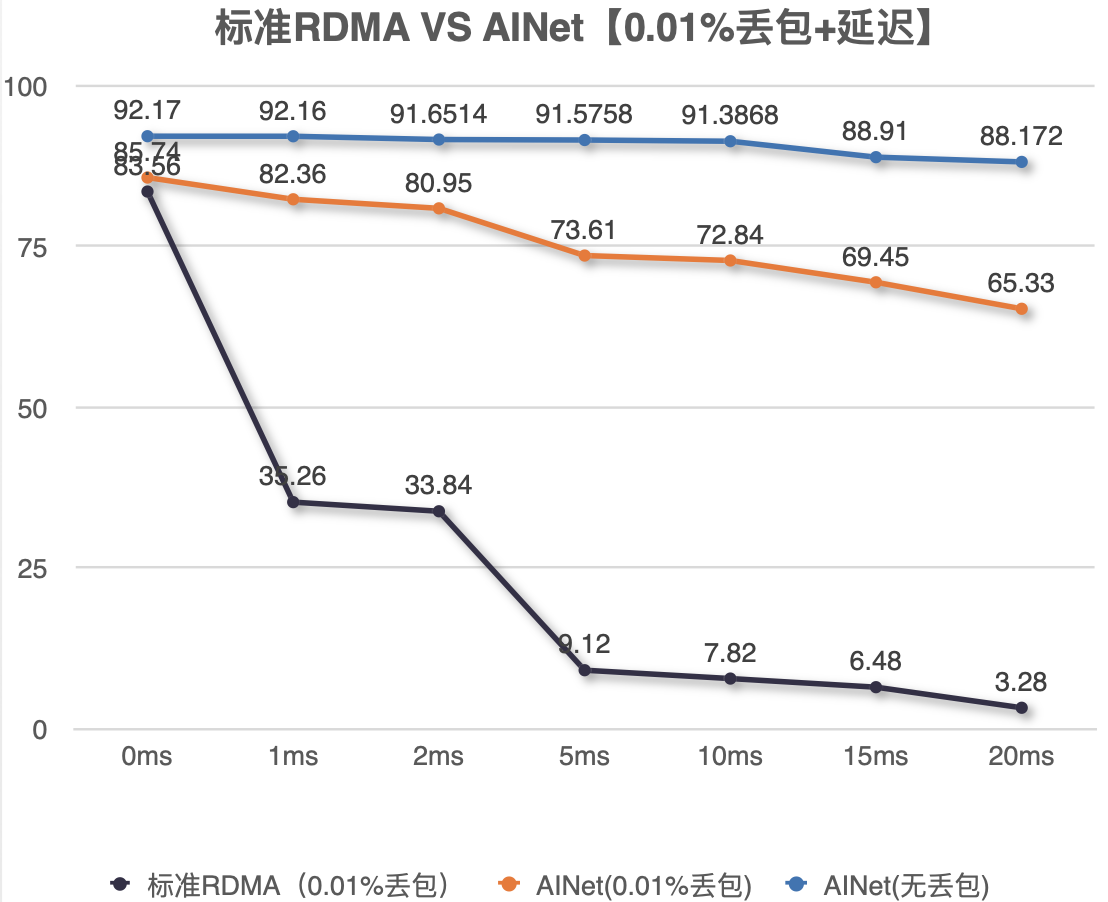
采用行业首创的 AINet 协议。
使用自研 SDN 交换机,连接城域 RDMA 网络。
跨多个 IDC 数据中心,将分布式算力统一纳管。
形成大型超高速互联的智能计算资源池,提升超高速并行计算的加速能力。
应用场景
立即体验 >>
AI 大模型训练
算力集群提供稳定且高性价比的计算能力,配备3.2Tbps RDMA高速网络和高性能存储系统,能够高效应对大规模分布式训练任务。这种配置尤其适合处理LLM模型在训练、推荐和搜索等应用场景中所需的大量数据和密集计算需求。
大模型分发推理
通过跨地域和跨云边的高速RDMA互联,实现了大模型的快速分发和边缘推理。同时,数据能迅速回传以支持模型的精细调优,从而有效地提供AI领域的大模型“CDN”服务。
科研及工程仿真
在流体力学、结构仿真、基因测序、石油勘探和生物制药等领域,为了推动或预测工业设计、分子结构等,通常需要进行大规模的仿真运算。因此,必须依托高性能算力集群,以显著提升并行计算的速度和效率。
H20 免费试用
海量模型服务限时免费
扫码加入社区
算力市场
GPU 服务
算力集群
模型服务
模型广场
帮助文档
如何选用 GPU
API 文档
快速开始
Q & A
相关链接
矩阵起源
©矩阵起源(深圳)信息科技有限公司 |
粤ICP备2021044820号